AWS Marketplace - Datasift Sandbox Documentation
- AlexI (Unlicensed)
- DrewS (Unlicensed)
IMPORTANT NOTICE (17 May 2014): Datasift recently changed their policy and SFTP push is now only available to enterprise customers. We will shortly be upgrading our service to use S3 as the interchange mechanism, which is still available to "Pay As You Go" users. In the meantime, this service is only usable by Datasift Enterprise Tier users.
Advanced topics breakdown:
- Suspending and deleting sources
- Creating aliases and discarding unwanted entities
- More complex analytics and visualization
- Exporting the data (and backups, and alerting)
- Importing other sources
- Adding users and communities
- Updating the software
Introduction
DataSift is the most sophisticated data platform used to filter insights from the world's most popular social & news sources. Infinit.e is the first Open Source document analysis cloud platform for collecting, storing, processing, retrieving, analyzing, and visualizing unstructured and structured data sources. This AMI merges the two capabilities to provide a cheap and easy on-demand application for collecting and storing volumes of social media, and critically to make sense of this data. Use Datasift's query editor to choose real-time streams; search and visualize the tweets, posts, or web pages in near real-time; pull in data from other sources from the Internet or enterprise; write big data analytics in javascripts or Hadoop.
Highlights:
- A single platform providing a unique combined capability: access to Datasift's social media aggregator, a storage platform with full text and faceted search, an extensible visualization platform, and a generic analytics framework.
- Use an intuitive visual interface to create and explore near-real-time data streams.
- View content, aggregations, and social networks generated from a fusion of twitter, facebook, reddit, blogs, and forum posts enriched with cutting edge natural language processing.
Launching an instance
From the Amazon AWS marketplace, either type Ikanow into the search bar, or navigate directly to our seller page via this link.
As seen in the screenshot below, there are four different products, and two Datasift AMIs in particular:
- Infinit.e/Datasift Social Media Analytics Suite.
- Infinit.e/Datasift Social Media Analytics Suite - RAID (for better performance ; higher EBS costs).
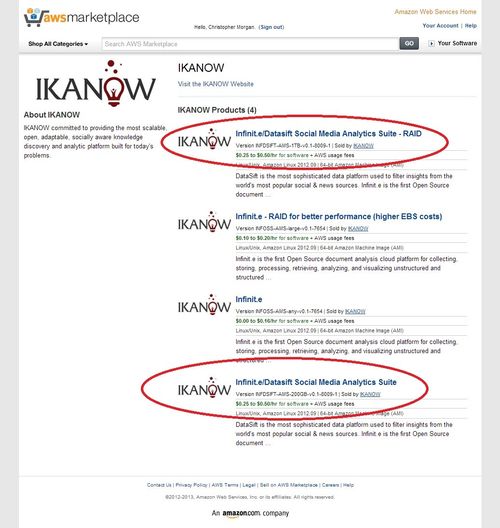
The second of these provides a 1TB 4-volume RAID-0 array and therefore provides higher speed and storage. The higher cost from Amazon of this storage will result in ~$150/month higher costs however. For smaller quantities of data (say 100,000 records) the cheaper version should provide perfectly adequate performance, and of course it is recommended to use the cheaper version while evaluating the platform (other than its performance!).
Following the product links, from the product page preparing to launch a server is as simple as logging in to Amazon (or creating an Amazon account) and pressing the "Continue button" (see screenshot below), deciding between the available instance types and launching. (The default security group, allowing 22, 80 and 443 should be sufficient for most purposes and can be changed later from the AWS console - note HTTP or HTTPS is necessary to access the GUI and SSH is necessary for the Datasift-Infinit.e data transfer, which occurs over SFTP).
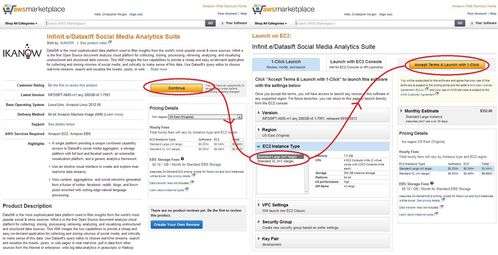
The available instance types are:
- m1.large: 2 core 7.5GB server: recommended for smaller numbers of records (up to 200,000)
- m1.xlarge: 4 core 16GB server: recommended for 200,000 or more documents
Once the instance has been launched, it will take about 5 minutes for the application to become available. The sections below describe the next steps.
Initial administrative tasks
Configuring Infinit.e
After the instance has been launched, it takes a few minutes for the platform to become available. Enter the hostname (eg "ec2-AAA-BBB-CCC-DDD.compute-1.amazonaws.com") into the URL bar of your browser and refresh until a login page appears, as shown below.
Log in using "infinite_default@ikanow.com" as the username and the instance ID as the password. The instance ID can be obtained from the "My Software Subscriptions" page of your Amazon Marketplace account.
The following steps are recommended (though not necessary) after install:
- Change the username and password of the Admin user
- (Less important, certainly while getting started) create a new non-admin user for day-to-day activities
Both of these can be accomplished from the Manager Web app. This can be launched from the "MANAGER" link at the top-right of the Infinit.e GUI after login, as shown below. You are automatically authenticated in the Manager Web app if logged into Infinit.e, and vice versa.
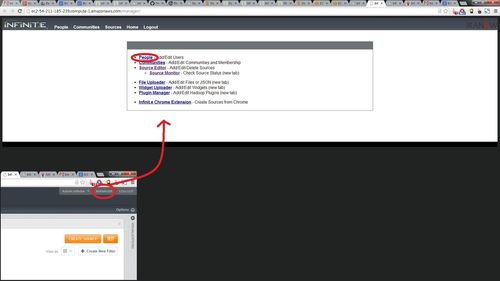
Select the people tab from the Manager home page and select "Admin Infinite" from the list of users on the left. You can change the first name, last name, email address (==username) and password: it is recommended to change the username and password at least.
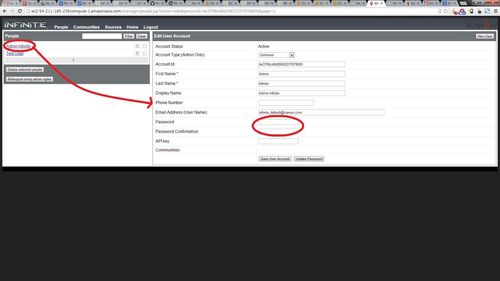
It is similarly possible to create a new user without admin privileges for browsing the data and (optionally) creating datasift sources. Simply select the "New User" button in the top right hand corner of the same "People" page, enter the First Name, Last Name, Email Address, and Password fields and select the "Create User Account" at the bottom.
In order to allow the new user to build data sources and entities, it is also necessary to change their role within their communities. Communities in Infinit.e allow segmentation of both data and user access rights. By default there is one shared community, the "Infinit.e System Community" (and each user has their own "Personal Community", which cannot hold data but is used for things like personalized settings and aliases being testing). The Manager Web app allows user to create new communities, to add/remove users, and to change users' permissions, this is discussed below.
Further information:
Registering and configuring Datasift
Once the immediate Infinit.e security-related configuration has been addressed, the connection to Datasift should be established.
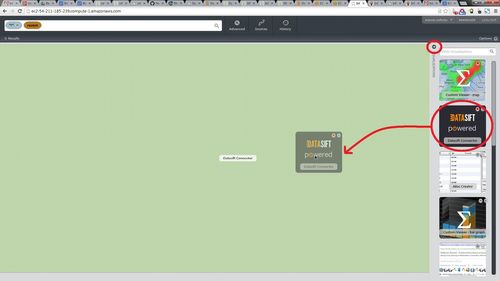
Returning to the main Infinit.e GUI (ie the previous tab from the Manager web app), the "Datasift Connector" widget should be already loaded (see below). If not, then it can be dragged into the workspace as follows (with reference to the screenshots below):
- Open the "visualizations" tray the main GUI (far right, at the top of the workspace).
- Locate the "Datasift Connector" with the "Powered by Datasift" logo in the tray
- Drag it into the workspace (or equivalently double click on it, or equivalently press the "+" button in the logo's top right corner).
For users without a Datasift account, it is necessary to register for one. This can be done by following this link, or equivalently by pressing the "Register!" button in the widget itself (note that this annoying button disappears forever once a user's connection to Datasift has been established once). For people just wanting to try out Datasift, the free trial provides ample free credit for testing and evaluation purposes (eg during the testing of this application, I imported about 10,000 tweets and facebook messages for ~$2).
Once a Datasift account has been created, two final steps are needed:
- Create recommended Datasift configuration
- Paste the Datasift username and API key into the Infinit.e "Datasift Connector" widget
Recommended Datasift configuration
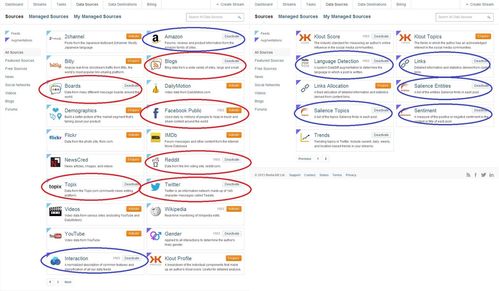
There are not many steps required, go to the Datasift Sources page, and enable two sets of things:
- The data sources, eg Boards, Topix, Amazon, Blogs, Reddit, Twitter (Note: selecting some sources may require you to sign individual license agreements to access that data).
- The augmentations:
- The following augmentations are on by default, free, and should be left on: Interactions, Klout Score, Language Detection, Links, Trends.
- The following are supported within Infinit.e but may not be useful for user's applications (and cost money):
- Links: Pulls out any URLs referenced within the documents (including twitter)
- The following are not explicitly supported by Infinit.e (but are still retained metadata, ie can be exploited with custom code): Klout Topics, Trends, Links Allocation.
- The following we recommend enabling if not on already to take full advantage of the Infinit.e platform:
- Salience Topics: Uses Natural Language Processing to identify fairly high-level topics (eg Sports/Business/Entertainment), also highlights key phrases in the content that are related to the topic.
- Salience Entities: Uses Natural Language Processing to extract entities like places, people and organizations.
- Sentiment: Uses Salience's Natural Language Processing engine to create sentiment scores for the title and content. Infinit.e assigns the content's sentiment to the author of the document.
Since this documentation was written, it seems that "Facebook Public" now shows "Enquire" not "Activate" and may require contacting Datasift to enable.
Further reading:
Connecting Datasift to Infinit.e
From the Datasift dashboard copy the "Username" and then the "API key" and paste them into the corresponding fields in the "Datasift Connector" widget:
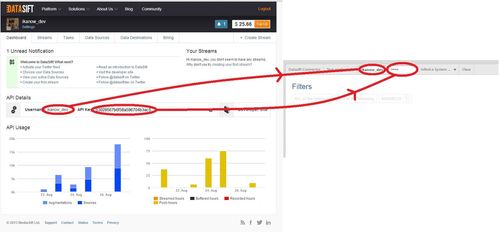
To check that the values were correct, press the "Test Credentials" button in the widget (see screenshot) below. The success pop-up also displays your remaining balance, and the username/API key is cached for the Infinit.e user that is logged in (the API key does not go out across the network again).
You are now ready to start building Datasift sources!
Building, testing, and activating data sources
There are three phases to building Datasift sources within Infinit.e, using the "Datasift Connector" widget described above:
- Using Datasift's query editor, embedded in the "Datasift Connector" widget, to create a filter (see screenshot below).
- Test the filter using the "Test" button on the widget header
- Publish the Infinit.e source for the desired community from the filter.
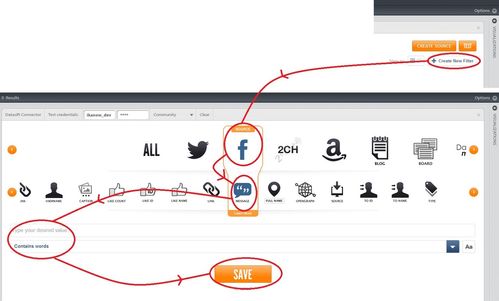
This section will focus on the second two of these activities, both because it is highly intuitive and also because Datasift's own web-site contains lots of documentation on the first of these (query editor, available operators, fields-that-can-be-filtered). The only difference is the two orange buttons "Create Source" and "Test" (see screenshot below), which perform Infinit.e-specific actions.
Once you have chosen a filter that you believe will collect the data you want, you can perform a simple test (note that for more granular testing, it is recommended to create a stream from the Datasift web-site, and then use the test function there.
To initiate a test from the "Datasift Connector" widget, simply select the "Test" button in the widget header (see screenshot below). After 10s or less, this will have one of two outcomes:
- A dialog will pop up showing titles for up to 10 retrieved documents (the test will terminate after either 10s or 10 documents)
- A dialog will pop up noting that no documents were retrieved, and will give you the option of running a longer (60s) test.
- For filters that collect documents slower than ~1/minute, you can either use the stream test from the Datasift web-site, or run the test every few minutes (the stream is cached by Datasift for some period between tests)
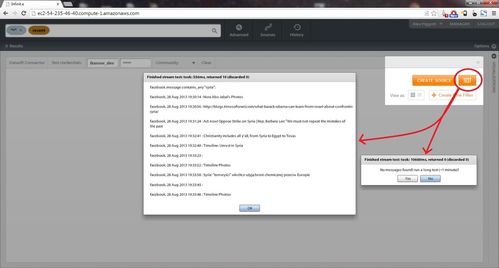
Note that the "Test" function does cost money to run, but because the time/number of documents returned is so limited, it is normally only a few cents.
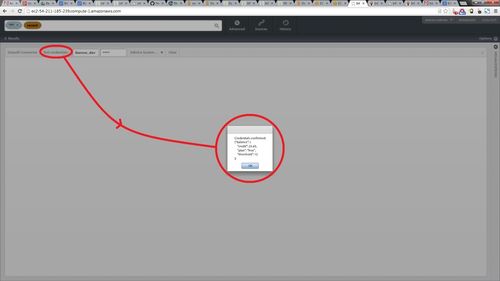
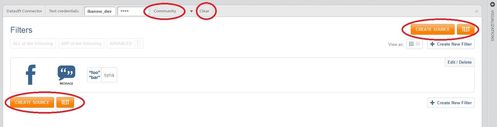
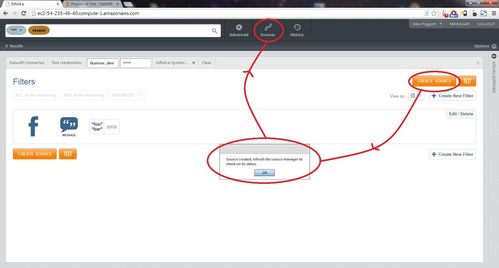
Once you have convinced yourself the filter is correct, it is time to publish the data source to Infinit.e:
- Select a community from the "Community" drop down - in the default configuration, this will always be the "System Community" (a later section discusses multi-community environments).
- Press the orange "Create Source" button, after a few seconds this will pop up a dialog box either confirming success of describing the error.
- As per the "success" dialog box bring up the "Source Manager" dialog and refresh to show the newly created source(s).
These steps are shown in the screenshot below:
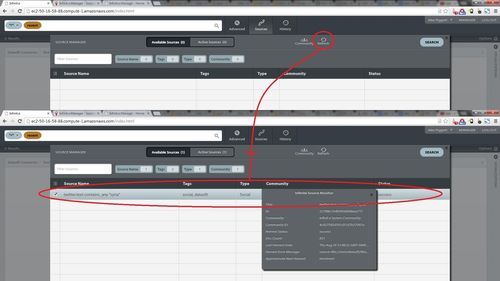
The role of the "Source Manager" dialog is to control which sources are included in queries, not as a monitoring function. To keep track of whether the sources are collecting documents, how many have been collected, which are suspended, etc, use the Source Monitor web app, by following the link on the Manager home page as shown below.
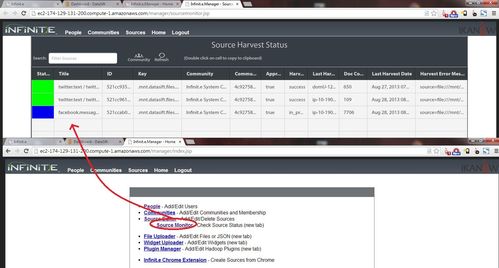
The filter used to create a source does not get automatically cleared after the source has been published, in case you want to create a similar filter for a new source. The "Clear" button in the widget header will remove the filter. Note that the currently displayed filter (or lack thereof) is saved between sessions.
A number of related topics are described later:
- Suspending/re-activating/deleting the source
- Modifying existing sources
Currently only "pushed" data is supported, not "recordings" or "historics". Both can be supported fairly easily, and we will add these features if there is enough interest. In addition managed sources are not explicitly support (again, these will be added if there is enough interest).
Further reading:
- Query Builder
- Historics
- Datasift targest and augmentations
- Source Monitor GUI
- Suspending and deleting sources
Basic exploration of the data
There is a general guide on using the Infinit.e GUI published here; this section will focus on Datasift-specific topics.
There are three general ways to explore the data obtained from Datasift from the Infinit.e GUI:
- Build queries to bring subsets of data into the GUI
- (see under "Searching Using Infinit.e" in the aforementioned guide; a full description of the query function is provided here, note many of the parameters map onto the "Advanced Options" tab, which is described below)
- For a given query, visualize the data in one of the many "widgets" that show different slices of the data and its aggregations
- (see under "Visualizations (Widgets)" and "Canvas" in the aforementioned guide; building your own widgets is described here).
- To drill down (filter) to a small number of documents you can temporarily select subsets of the data from one widget and see how it affects other widgets.
- (see under "Filtering" in the aforementioned guide)
The data in documents is represented as lists of "entities" (see below for a list of the entities supported with the Datasift connector), and associations (links between 2 entities, or between an entity and a place, or an entitiy and a time). Entities can optionally have a sentiment number, which represents whether the text mentioning the entity is positive or negative in tone. An example of this decomposition is shown below for one document. The full JSON data model can be found here.
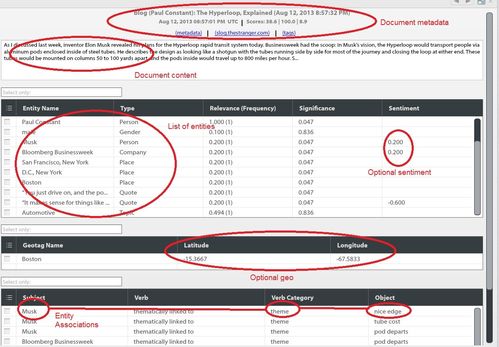
The general visualization approach is to show aggregated statistics - eg the sum/average of sentiments, the frequency/importance of entities and associations, document or entity counts by hour/day/week, or clustered by geo etc.
Before diving into the graphical views, however, one widget that is useful for getting an overview of the data is the "Query Metrics" widget, see screenshots below:
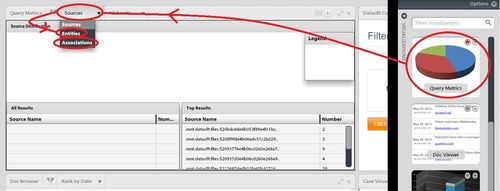
Ignore the "Source" view and select instead "Entities" and then "Associations".
The "Entities" view shows the different types of entity extracted either from the Datasift metadata or from the Salience NLP. Most of the types will be from the following:
| Entity Type | Example | Description | Source |
|---|---|---|---|
| Topic | Business, Sports, Politics, Health, War, Law, Crime, Automotive, Investing, Weather, "Software and Internet", Economics, Food, Science, Aviation, Education,"Video Games", Technology, Labor, Art, Travel etc | A high level topic inferred from the contents by the Natural Language Processing. | Salience |
| Gender | Male, Mostly_Male, Female, Mostly_Female, Unisex | Obtained from the Datasift "gender" augmentation, an estimate of the gender of the document's author. | Datasift |
| FacebookUser | "Mark Zuckerberg", IKANOW, "Facebook Birdwatching Group" | For Facebook documents, any of the people/companies/groups with Facebook accounts mentioned in a post (including the author). | Datasift |
| TwitterUser | twitterHandle (ie without the leading'@') | For tweets, any of the people/companies/groups with twitter accounts mentioned in a post (including the author). | Datasift |
| RedditUser | witty_handle_here | For reddit posts, the author's account name. | Datasift |
| Person | "John Stewart" | For any other document type (blogs, news, forums) the author is categorized as a Person. Note that the Person type is also used for names extracted from the content using NLP. | Datasift (or Salience) |
| Hashtag | iwanttotrend (ie without the leading '#') | Hashtags in tweets. | Datasift |
| City | "New York, NY, United States" | Locations can be obtained in one of two ways: the registered location of the author (from Datasift), or places mentioned in the content (extracted using NLP). If the place can be geolocated by Infinit.e to a city, then this type is used. | Datasift/Salience |
| Region | "Maryland, United States" | Locations can be obtained in one of two ways: the registered location of the author (from Datasift), or places mentioned in the content (extracted using NLP). If the place can be geolocated by Infinit.e to a state or similar adminstrative partition, then this type is used. | Datasift/Salience |
| Place | "White House", "Arizona", "US" | Locations can be obtained in one of two ways: the registered location of the author (from Datasift), or places mentioned in the content (extracted using NLP). If the place cannot be geolocated by Infinit.e then this "catch all" is used. | Datasift/Salience |
| URL | http://www.ikanow.com/downloads | Links in Facebook posts and tweets. | Datasift |
| Person | "Barack Obama" | A name extracted from the content by Salience and believed to be the name of a person. | Salience (or Datasift) |
| Job Title | President, CEO | A job title extracted from the content using Natural Language Processing. | Salience |
| Company/Organization | Microsoft, UN | A name extracted from the content by Salience and believed to be the name of a company or organization. | |
| Quote | "Ask not for whom the bell tolls" | An unattributed quote extracted from the content. | Salience |
| Keyword | "american history", "domestic spying program" | A word or phrase from the content that is statistically significant to the meaning of the post. | Salience |
The "Associations" view shows the different "verb categories", ie the top level type of the association between entities. The following association types are generated:
| Association Type | Example | Description | Source |
|---|---|---|---|
| theme | "President Obama/Person is thematically linked to (theme) Mortgage Advice/Keyword" | A link in the content between keywords and entities such as people/places/companies (eg an important sentence containing both) | Salience |
| topic | "Alex Piggott/Person writes about (topic) Software/Topic" | An association from the author of a post to its topics | Salience |
| hashtag | "gamerd00d/TwitterUser tweets about (hashtag) guildwars2/Hashtag" | An association from the author a tweet to the hashtags contained therein, eg @gamerdood: "wow #guildwars2 is the best game ever" | Datasift |
| mentions (twitter) | "upAllNight/TwitterUser mentions (mentions) gamerd00d/TwitterUser" | An association from one twitter user to another based on a mention, eg @upAllNight: "@gamerdood that was crazy!!!" | Datasift |
| mentions (facebook) | "Alex Piggott/FacebookUser mentions (mentions) IKANOW/FacebookUser" | When one Facebook user mentions another in a post. | |
| retweets | "gameReviews/TwitterUser retweets gamerd00d/TwitterUser" | An associated from one twitter user to another based on a retweet, eg @gameReviews: "Seems like the punters are enjoing it @gamerdood RT wow #guildwars2 is the best game ever" | Datasift |
| likes | "IKANOW/FacebookUser likes (likes) Open Analytics Group/FacebookUser" | An association from a Facebook user who likes a post by another Facebook user. | Datasift |
Note that there are two views of the entities and associations: "All Results" and "Top Results" (see screenshot) - the first of these shows the top 100 or so entities/associations (see below), the second shows all of the entities/associations within the top 100 documents (normally more than the "All Results"). Both should be inspected to get an overview of the data.

Note that the number of aggregated entities and associations to be returned can be controlled by the advanced options page, see below (together with various other parameters: including the number of documents to bring back into the workspace and the granularity of the temporal aggregation in the timeline widget). There is obviously a trade-off between fidelity and performance (and the defaults seem to be a good compromise across a variety of use cases).
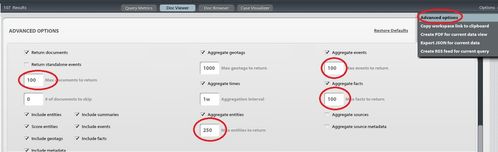
Here is a quick list and description of the other widgets:
Basic Infinit.e Widgets |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
|
|
|
|

|

|

|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
- Doc Browser: View the individual documents and their metadata, ranked by score or date, together with their entities.
- Useful for analyzing specific documents once filtering or querying has reduced the dataset to manageable size.
- Entity Significance: View the entities across all documents, ranked by score or frequency.
- Useful for seeing the entities that are common or significant within a dataset.
- Sentiment: View any entities with sentiment, across all documents, ranked by score or frequency, or various sentiment statistics.
- Useful for viewing high level sentiment of entities at a glance.
- Map: Show geo-tagged documents and events, and places mentioned in the content.
- Useful for visualizing the geographic distribution of the social media in the queried dataset.
- Timeline: Shows documents and document counts over time.
- Useful for longer running Datasift sources to see how the volumes change and
- Event Graph: Shows a link analysis chart of associations.
- Useful for visualizations of subsets of social networks, or for viewing topical/thematic relationships between content publishers.
- Event Timeline: Shows timestamped associations between entities over time, including the start/end times of long running associations.
- Useful for seeing the temporal aspect of social networks (the event graph does not include time as a dimension)
- Entity Alias Builder: combine different entities representing the same eg person, or discard unwanted entities. See this section in the advanced topics.
- Custom Viewers - map and bar graph: for simple visualizations of custom analytics generated using the plugin manager. See this section in the advanced topics.
Some other (non Datasift) use cases illustrating how the widgets can be used is at the bottom of this section of the open source platform overview.
One final thing to note is that it is possible to build your own widgets, either from scratch using our eclipse plugin, or starting with one of our open source widgets. Once built, they can easily be uploaded into the application,
Further reading:
- Infinit.e "quick start" guide
- Entity Alias Builder
- Creating and visualizing custom analytics
- Other use cases
Advanced Topics
- Suspending and deleting sources
- Creating aliases and discarding unwanted entities
- More complex analytics and visualization
- Exporting the data (and backups, and alerting)
- Importing other sources
- Adding users and communities
- Updating the software
Videos
Outline concept (1.25 minutes):
Configuring Infinit.e and Datasift (5.5 minutes):
Creating and activating data sources using the Datasift Query Builder (5.25 minutes):
Basic Exploration of the Data (6.5 minutes):
Controlling Datasift Sources (1.75 minutes):
Creating Aliases and Discarding Unwanted Entities (2.5 minutes):
Contacting Us
We have set up a github page for this application, where we and the community can post and track issues and questions, and to host any shared artifacts (eg interesting analytics scripts, new widgets etc).
Our general issue and question forum is here.
IKANOW can also be reached at support@ikanow.com