Understanding the code
Overview
These 2 sections give a brief top level introduction into how you would follow the code to understand the lower level design of Infinit.e.
Understanding the object model
This JSON format includes specifications for all the relevant objects.
The POJO definitions are all contained within infinit.e.data_model. This library has a particular package format:
- store contains objects that persist in MongoDB
- index contains objects that persist in ElasticSearch
- api contains objects that pass transiently through the (RESTlet) API
- Also:
- utils contains interfaces needed to build standalone Harvest extractor modules
- driver contains the (ever Beta) Infinit.e Driver
- custom contains Mongo/Infinit.e/Hadoop connector classes
"store" and "index" sub-packages map onto the collections ("tables") described here (final diagram, reproduced below). The names are not exact but are close enough it should be obvious. "api" sub-packages map (closely) to the REST structured described here.
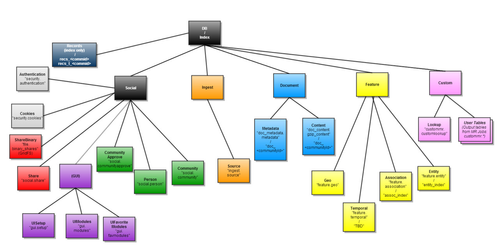
Within a sub-package, there are a small number of classes, the JSON specifications of which are described here.
As an example, documents persist in MongoDB, hence reside under "store.document". Because they can be passed out via the API and mirrored in the real-time index, there are also "transformer" classes in "index.document" and "api.knowledge".
Understanding the data flow
Various data flows are shown here (3rd diagram, reproduced below). The packages map onto the libraries here.
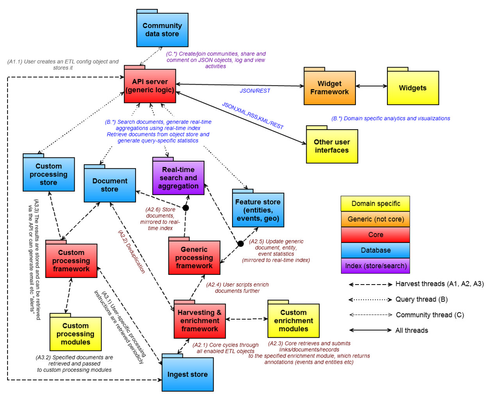
For example, once documents get to the end of the source pipeline (packge harvest.library, controller HarvestController - see the data flow here), they are passed to the generic processing package, where a few things happen:
- The StoreAndIndexManager first stores the /wiki/spaces/INF/pages/4358642 in the doc_metadata and doc_content collections via MongoDbManager, and then mirrors it (in a Lucene optimized format transformed via document.index) in the corresponding Lucene index using ElasticSearchManager.
- The AggregationManager aggregates the entity and association JSON objects in feature.entities and feature.associations, and then mirrors them (in a Lucene optimized format via document.index) in the corresponding Lucene index using ElasticSearchManager.
Note that the details of the Lucene format is relatively uninteresting, because it is completely driven by elasticsearch's implementation of a Lucene engine, and is very abstracted away from almost all developers and users via the query object.
Copyright © 2012 IKANOW, All Rights Reserved | Licensed under Creative Commons