Introduction
Welcome to the IKANOW Community Edition (Infinit.e) landing page! This sub-site is intended for integrators, developers, IT staff, technical analysts, researchers and similar roles, who want a technical overview of the platform and technical information about how to install, configure, exploit, integrate, or extend it. For a higher level view, check out the following links: In the spirit of the sort of analysis we would like to support, we will provide the remainder of this overview using the "5 Ws". |
|
 Who?
Who?
We are IKANOW, the developers of Infinit.e, the first Open Source document analysis platform. Our vision is to enable agile intelligence through open analytics.

What?
IKANOW Community Edition is a scalable framework for collecting, storing, processing, retrieving, analyzing, and visualizing unstructured documents and structured records. It is built with IKANOW Infinit.e, Hadoop, Elasticsearch, and MongoDB.
Click on zoom button above to expand
Let's provide some clarification on each of the often overloaded terms used in that previous sentence:
- It is a "framework" (or "platform") because it is configurable and extensible by configuration (DSLs) or by various plug-ins types - the default configuration is expected to be useful for a range of typical analysis applications but to get the most out of Infinit.e we anticipate it will usually be customized.
- Another element of being a framework is being designed to integrate with existing infrastructures as well run standalone.
- By "scalable" we mean that new nodes (or even more granular: new components) can be added to meet increasing workload (either more users or more data), and that provision of new resources are near real-time.
- Further, the use of fundamentally cloud-based components means that there are no bottlenecks at least to the ~100 node scale.
- By "unstructured documents" we mean anything from a mostly-textual database record to a multi-page report - but Infinit.e's "sweet spot" is in the range of database records that would correspond to a paragraph or more of text ("semi-structured records"), through web pages, to reports of 10 pages or less.
- Smaller "structured records" are better handled by structured analysis tools (a very saturated space), though Infinit.e has the ability to do limited aggregation, processing and integration of such datasets. Larger reports can still be handled by Infinit.e, but will be most effective if broken up first.
- By "processing" we mean the ability to apply complex logic to the data. Infinit.e provides some standard "enrichment", such as extraction of entities (people/places/organizations.etc) and simple statistics; and also the ability to "plug in" domain specific processing modules using the Hadoop API.
- By "retrieving" we mean the ability to search documents and return them in ranking order, but also to be able to retrieve "knowledge" aggregated over all documents matching the analyst's query.
- By "query"/"search" we mean the ability to form complex "questions about the data" using a DSL (Domain Specific Language).
- By "analyzing" we mean the ability to apply domain-specific logic (visual/mathematical/heuristic/etc) to "knowledge" returned from a query.
We refer to the processing/retrieval/analysis/visualization chain as document-centric knowledge discovery:
- "document-centric": means the basic unit of storage is a generically-formatted document (eg useful without knowledge of the specific data format in which it was encoded)
- "knowledge discovery": means using statistical and text parsing algorithms to extract useful information from a set of documents that a human can interpret in order to understand the most important knowledge contained within that dataset.
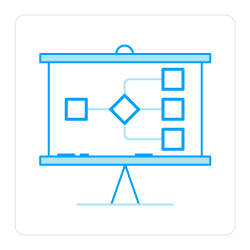
One important aspect of the Infinit.e is our generic data model. Data from all sources (from large unstructured documents to small structured records) is transformed into a single, simple. data model that allows common queries, scoring algorithms, and analytics to be applied across the entire dataset. The following diagram (click zoom to expand) illustrates this:
The following thumbnails (click to expand) show a complex query being built, and an examples of visualizing the knowledge encoded in documents returned from the query. Note that although the screenshots show our webapp being used, in practice the Infinit.e platform can be integrated with any open front-end application or analytical chain.


Why...
... did we build it?
While supporting information analysts for the military and Government, we observed that the landscape of professional analysis tools is dominated by expensive proprietary products with limited flexibility, vendor lock-in, and requiring extensive and continuing customization which ends up extremely expensive and inefficient.
Further, these tools had often originally been designed to analyze and mine structured records, whereas increasingly data is generated in a mix of unstructured documents and traditional structured records. Usually, unstructured documents dominate structured records in terms of readily available intelligence to be gleaned.
So we believed there was a gap in the market, if it could be filled.
We also observed that the Open Source community was developing tools that provided many of the core functions needed for an unstructured document-centric analysis tool (storage, search, aggregation, analytic frameworks). This provided some exciting new opportunities:
- To lower the cost of developing an analytic platform, eliminating traditional cost barriers to its use, and freeing effort to focus on domain and analyst specific functionality and process
- To helps the platform remain up-to-date, since the OSS tools are in continuous development and the ecosphere in general is very active.
- Finally, to foster an active open community of developers and users, in the image of the OSS projects on which the platform is built.
Further, the increasing richness and availability of low cost SaaS and PaaS cloud services meant that great functionality, like NLP, and great computing performance scalability using platforms like EC2, were affordably available for smaller organizations.
Based on these needs and opportunities, we built Infinit.e, the first Open Source document analysis cloud platform, using great OSS projects like Lucene, elasticsearch, Hadoop, Mahout, MongoDB, tomcat, and many others. Our objectives are:
- To provide, maintain, and enhance an "Internet-scale" document analysis platform based on the currently best available mature Open Source projects.
- To continue to develop the functionality based on analyzing and abstracting real users' requirements.
- To make the platform's source available to everyone under standard Open Source licenses.
- To provide a simple but powerful front end to enable and demonstrate the platform's most important capabilities.
- To help organizations customize the tool to align to their existing processes/tradecraft, as well as to take advantage of new opportunities afforded by the tool's functionality.
- To build more focused, smaller scale, applications using modified versions of the platform (eg for performance/scale vs functionality).











Key OSS and cloud technologies used in Infinit.e
... might you want to use it?
The platform is intended to support any activity where analyzing and synthesizing large volumes of data can provide a benefit; and particularly where the conclusion is sufficiently complex that the human brain is still needed, but the volumes of data are high enough that the brain could use some help!
Specific examples include, but are not limited to:
- Business analysts:
- Find out key people associated with organizations and products.
- Predictive analytics to determine eg likely stock movements, product release dates, etc.
- Sentiment analysis and social media monitoring.
- Journalists:
- Understand quickly related entities and concepts to people and organizations.
- Local blog and social media analysis, incorporating social media analysis, to determine resident's issues of concern.
- Universities:
- Use a free and open analytics platform for teaching and research for both analysis and data analytics, and a combination of the two.
- Law enforcement analysts:
- Eg unstructured analysis on police reports to identify "hidden" trends in criminal activity.
- Potentially combined with social media and local blogs to correlate local sentiment and reports against criminal activity.
- Military analysts:
- Geo-spatial and temporal analysis of incident reports
- Analysis of forum posts to identify authorities on particular (eg) regions, local cultures etc
- Intel analysts:
- Mining and synthesizing large amounts Open Source material from the Internet as part of OSINT activities.
- Pulling out topics and trends from Intel reports, analysis of competing hypotheses, ranking unusual keywords and entities, etc.
- Application developers:
- Can form the platform for mobile and desktop applications that depend on information about the real world, particularly where that information (eg Wiki pages, needs to be summarized or analyzed in some domain-specific way to be useful).
Illustrations of the diverse uses of knowledge discovery:
Market research using Infinit.e:

Analyzing crime statistics in DC

Due diligence (longer; using the enterprise edition)

 When?
When?
Starting with prototypes developed in early 2010, we started the main development of the tool in November 2010, focusing on adopting the best OSS tools for the tool's different functions, productionizing their use, and glueing them together in a logical way.
We released the first Open Source version in March 2012, with the core code mostly licensed under the Affero GPL license, and the API licensed under the Apache 2.0 license (together with plugins and utilities, and with one core library: the data model, which provides useful classes and utilities for serialization and deserialization of commonly-used JSON objects).
Development continues: check out our roadmap.
How...
- ... to learn more about the platform: click here for further details about the architecture, here are some details on our near-term roadmap.
- ... to download, install, maintain, and troubleshoot the platform: click here (troubleshooting guide here).
- ... to import data into the tool and perform basic analysis: click here.
- ... to develop and install plugins and visualizations: click here.
- ... to integrate with other platforms: Infinit.e contains a rich and open REST API, described here. The API documentation includes "tutorials" (here) on performing many common operations using the API.
- ... to download and develop core infrastructure: the Open Source repository is here, information about building and developing the code is here.
- ... to get support: Contact us at support@ikanow.com or post issues on our github page.