...
The dataset summarizer is an analytic module accessible via the GUI Utilities - Plugin Manager. It is intended to give analysts a quick understanding of large unfamiliar semi-structured datasets.
...
Running the dataset summarizer
TODO
1) select, copy, change title
2) set query
3) configure
...
Configuration
Navigate to the plugin manager
Select the "SourceAnalyzerTemplate":

From the same dropdown, now change the selection to "Copy Current Plugin" - this will create a copy from the template:
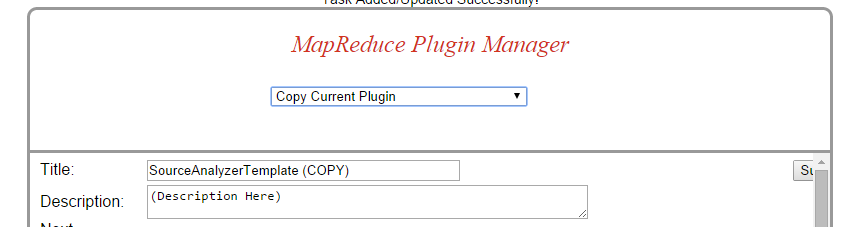
Set the Title and Description and press "Submit" (you can just see the button in the far right in that screenshot)
Now select the data to run over:
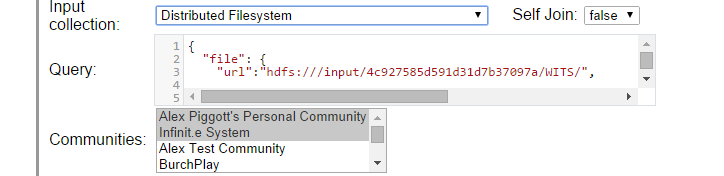
The Input Collection can be one of the following:
- Distributed Filesystem - to read from HDFS
- Document Metadata Collection - to read from already ingested "Infinit.e" documents
- The output from any custom job
For files, the same syntax as the File extractor is used. For Documents, either a MongoDB-style or an Infinit.e query can be used. For custom results, a MongoDB-style query can be used. These topics are covered in more detail here.
Setting the communities has two effects:
- For documents, it restricts the input data to documents from those communities
- For all input types, it sets the access permissions on the output
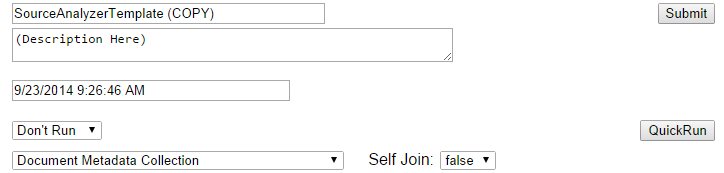
Finally, set the configuration in the "User arguments" text area:

The configuration JSON is specified below.
Execution
The "Save and Debug" button shown above is useful for sanity-testing the output before big runs. Note that it overwrites any existing results, so use with caution.
To run on the full dataset specified, either press the "Quickrun" button (not recommended for larger datasets - it just polls the API until done), or change frequency from "Don't Run" to "Once Only" and then "submit"
The output can be viewed in a separate tab from the "Show results" button:
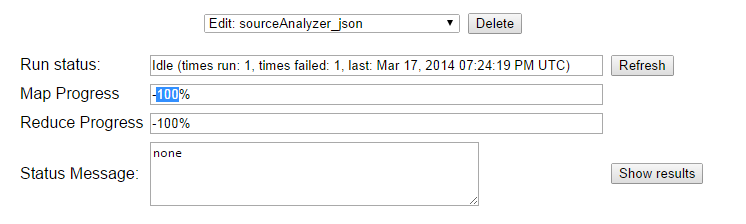
The output format is described below.
Configuring the dataset summarizer
...